I have been reading Optimized C++ by Kurt Guntheroth for sometime now and it's quite a remarkable book. It's one of the must read books for C++ programmers who wish to write high performance C++ code.
I will discuss one section in this book which explains about caches.
The speed of main memory access is very slow compared to speed of the processor. In fact, by the time a single word is fetched from the main memory, CPU can execute hundreds of instructions. Hence memory access can bring down the performance and throughput of the entire system. To alleviate this problem, modern and desktop class machines have various levels of caches, which are much faster. The caches are situated close to CPU so that they can be accessed much quicker compared to the main memory.
I will explain further with an example of my own laptop
My desktop machine has Intel Core i7 7700HQ processor. The processor has 4 physical cores. Each core has three levels of caches - L1 instruction cache, L1 data cache, L2 cache and L3 cache. L1 is closest to the core, followed by L2 and then L3.
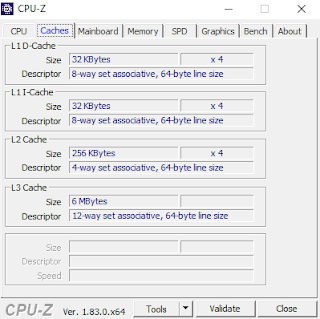
The amount of cache memory also decreases as we from L3 cache (6 MB) to L1 cache (32 KB).
In the descriptor field of each cache, we can see 64 byte line size.
The significance of this is, since memory access is slow, when the core needs to read a variable of a single char (1 byte), it still fetches 64 bytes ( including our data of interest ) of nearby data, to save time, anticipating that the surrounding data might be required for the upcoming instructions.
The fastest location from where the core can access the data is the registers. If the data is not already present in the registers, then L1 is searched. If not found (cache miss), then L2 is searched. If not found (cache miss), then L3 is searched. If there is a cache miss again, then we fetch the data from the main memory.
Also note that to make room for the new data from the memory, some data needs to be flushed from the caches. The most popular mechanism for this is to identify and evict least recently used data ( LRU ).
Cache and cache line size has direct impact on performance of the program, and hence the choice of our data structures and algorithms.
For instance, the elements of vector or array of ints is stored in one contiguous memory location. So if we fetch one element, we read the next 7 elements for free. Contrast this to the std::list of ints, (which is implemented as doubly linked list), where the elements are not contiguous. The performance is much slower, since we might have to fetch each element directly from the main memory.
Cache also has interesting implication on the design of a function / procedure. Since the least recently used data is evicted from the cache, our function should use the variable that we have read, preferably in quick succession or in a tight loop. If we read a variable, then use it once in the beginning, then again in the end, there are chances that the second access might read from the memory. ( which is slow). Hence, we have to declare variable as close as possible to it's usage (compiler might optimize or reorder statements to make the code more cache friendly even if we don't. )
We must also declare the most used data (hot data) of our class, in the first 64 bytes of the class declaration. This makes sure that whenever an object is loaded, we get the first 64 bytes in the cache.
There is one small adverse affect of fetching 64 bytes in one shot, resulting in false sharing of variables and decrease in the performance of the code. I will write about this in the future
I will discuss one section in this book which explains about caches.
The speed of main memory access is very slow compared to speed of the processor. In fact, by the time a single word is fetched from the main memory, CPU can execute hundreds of instructions. Hence memory access can bring down the performance and throughput of the entire system. To alleviate this problem, modern and desktop class machines have various levels of caches, which are much faster. The caches are situated close to CPU so that they can be accessed much quicker compared to the main memory.
I will explain further with an example of my own laptop
My desktop machine has Intel Core i7 7700HQ processor. The processor has 4 physical cores. Each core has three levels of caches - L1 instruction cache, L1 data cache, L2 cache and L3 cache. L1 is closest to the core, followed by L2 and then L3.

The amount of cache memory also decreases as we from L3 cache (6 MB) to L1 cache (32 KB).
In the descriptor field of each cache, we can see 64 byte line size.
The significance of this is, since memory access is slow, when the core needs to read a variable of a single char (1 byte), it still fetches 64 bytes ( including our data of interest ) of nearby data, to save time, anticipating that the surrounding data might be required for the upcoming instructions.
The fastest location from where the core can access the data is the registers. If the data is not already present in the registers, then L1 is searched. If not found (cache miss), then L2 is searched. If not found (cache miss), then L3 is searched. If there is a cache miss again, then we fetch the data from the main memory.
Also note that to make room for the new data from the memory, some data needs to be flushed from the caches. The most popular mechanism for this is to identify and evict least recently used data ( LRU ).
Cache and cache line size has direct impact on performance of the program, and hence the choice of our data structures and algorithms.
For instance, the elements of vector or array of ints is stored in one contiguous memory location. So if we fetch one element, we read the next 7 elements for free. Contrast this to the std::list of ints, (which is implemented as doubly linked list), where the elements are not contiguous. The performance is much slower, since we might have to fetch each element directly from the main memory.
Cache also has interesting implication on the design of a function / procedure. Since the least recently used data is evicted from the cache, our function should use the variable that we have read, preferably in quick succession or in a tight loop. If we read a variable, then use it once in the beginning, then again in the end, there are chances that the second access might read from the memory. ( which is slow). Hence, we have to declare variable as close as possible to it's usage (compiler might optimize or reorder statements to make the code more cache friendly even if we don't. )
We must also declare the most used data (hot data) of our class, in the first 64 bytes of the class declaration. This makes sure that whenever an object is loaded, we get the first 64 bytes in the cache.
There is one small adverse affect of fetching 64 bytes in one shot, resulting in false sharing of variables and decrease in the performance of the code. I will write about this in the future
Cache friendly C++ code
 Reviewed by zeroingTheDot
on
February 04, 2018
Rating:
Reviewed by zeroingTheDot
on
February 04, 2018
Rating:
Reviewed by zeroingTheDot
on
February 04, 2018
Rating:





Hello There,
ReplyDeleteThanks for highlighting this and indicating about
cppatomic where more study and thought is necessary.
I started to program with C and have some programming in JAVA. However, I have a small understanding problem with the following simple code below.
I understand that at the command "while (isspace(ch=getc(in)))" the programm reads till if founds a character that is either a " or a blank. This symbol is assigned to the variable delim.
Is it then correct to say that the program starts again at the same position as before and continues to read the string till "((ch=getc(in))!=delim)" is fulfilled?
THANK YOU!! This saved my butt today, I’m immensely grateful.
Gracias,
Pranitha